
I’ve been to a couple of amazing SIGGRAPH conferences now, and I’m the first to admit that most of the research presented in the Technical Papers is way beyond me. But I always remain fascinated by this part of the proceedings, and every now and then something you see at SIGGRAPH finds it way into some mainstream tech or a feature film, or, these days, a VR application or hardware.
Enter Hao Li, an Assistant Professor of Computer Science at USC and now Director of the Vision and Graphics Lab at USC ICT. He’s also the CEO and Founder of AR and face swapping start-up Pinscreen (which I wrote about here). Hao’s area of expertise is performance capture, digital humans, faces and VR. And a combination of all of these.
It’s not surprising then that research he is part of is being presented at SIGGRAPH Asia 2016 in Macao (5-8 December) in the area of facial and speech animation for VR head mounted displays. Actually, the full citation of the paper is:
HIGH-FIDELITY FACIAL AND SPEECH ANIMATION FOR VR HMDS
Kyle Olszewski, Joseph J. Lim, Shunsuke Saito, Hao Li
ACM Transactions on Graphics, Proceedings of the 9th ACM SIGGRAPH Conference and Exhibition in Asia 2016, 12/2016 – SIGGRAPH ASIA 2016
I had a chat to Hao about what this all means. Of course, for more in-depth info you can read the paper, watch the video below, or attend SIGGRAPH Asia in Macao to see this and many other great technical papers. I’ll be there too, so come say hi!
vfxblog: What is the idea behind this research – what was the problem you set out to look into?
Hao Li: In this research we wanted to address two main challenges.
First, can pure optical sensors (RGB cameras) be used to capture full facial performances of a person wearing a VR HMD? If this is possible, low cost cameras could be integrated in future VR devices and produced at scale. We have shown that a mouth facing camera and two integrated cameras in the VR HMD lenses can capture most parts of the face including eye brows and other important regions occluded by the HMD. For future devices that need to be capable for social VR applications, these sensors could be essential.
Secondly, much like Pixar animations have abstracted and stylized characters but highly compelling animations, we wanted to explore techniques that can transfer high-fidelity expressions and speech animations from a real person to a digital avatar. After years of research, we have noticed that the raw outputs of existing and state-of-the-art real-time facial tracking techniques are still affected by the uncanny valley, especially due to the low dimensionality of mapping techniques.
This work investigates the use of deep learning to address this high-dimensional mapping problem and produces high-quality speech animations using deep convolutional neural networks trained with animation curves created by professional digital artists.
vfxblog: Why is high fidelity expression important in VR?
Hao Li: The uncanny valley problem exists for the appearance of a digital avatar as well as for its motion. In the case of motion, especially during speech animation, the lips of real people generally undergo highly complex deformations. If the lip motions are not faithfully reproduced, we can perceive the animation as bad lip synchronization and artificial, which yields an unpleasant effect. Just like any form of face-to-face communication, it is critical to get across every nuanced and to make the experience as comfortable as possible.

vfxblog: Can you explain what a deep convolutional neural network is and how it was utilized here?
Hao Li: A deep convolutional neural network (CNN) is a type of neural network that consists of multiple layers of receptive fields. Each layer consists of combinations of convolutional and fully connected layers and some non-linear functions. The layers have also parameters that consists of learnable filters, which can effectively learn visual structures when trained with large amounts of image data.
We trained such CNN using input images of face recordings associated with animation curves provided by a professional artists. After training, we use the CNN to infer high-quality animation curves based on a every input frame during the performance capture.
vfxblog: How was your VR HMD prototype put together?
Hao Li: We used a FOVE HMD which has integrated cameras inside the lenses of the VR device. The camera can capture the eye regions with the help of IR LEDs surrounding the eye. Similar technologies for eye gaze tracking are also offered by SMI Vision. In addition to the existing sensors, we attached a $10 playstation eye camera with a fish lens camera right on the HMD facing the mouth. This region is lit with additional LEDs.
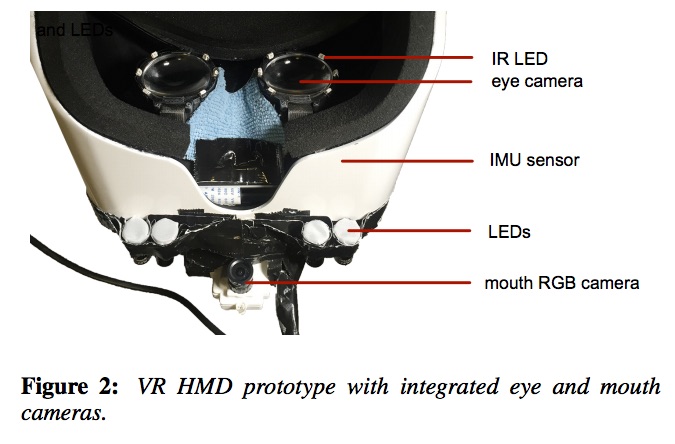
vfxblog: Can you outline what you were able to achieve in terms of tracking facial expressions and driving a digital avatar?
Hao Li: We were able to demonstrate the first real-time performance-driven facial animation with artist-quality speech animations using our CNN approach. This was previously only possible manually, and using facial rigs that need to be hand-customized for specific characters. Our method is completely automatic and works on any user and any target.
vfxblog: Can you talk about ways this drew upon existing tools and research in facial tracking/animation, and why you took a different or similar approach?
Hao Li: Existing facial animation techniques are based on capturing a facial performance, tracking its performance using a dedicated model, and the facial expressions analyzed and transferred to the rig of another character.

Since the dedicated tracking model is engineered to fit a wide range of people and expressions, we propose an end-to-end learning approach that can map the input directly to the retargeted animation. In analogy to many fundamental problems in computer vision we show that a deep learning approach for this regression tasks can outperform any hand crafted models.
vfxblog: Where do you see this being used and what future work needs to be done?
Hao Li: As long as optical imaging will be used for facial performance capture and retargeting, I believe that a similar deep learning framework will replace any traditional face tracking approach.
Furthermore, I think that, should VR become the future platform for immersive social communication, then the ability to sense faces will be indispensable just like the ability to build avatars. Both at USC and at my startup Pinscreen, we are developing technologies to make this accessible to the masses.
For more information about what’s on at SIGGRAPH Asia 2016 in Macao, check out the website: http://sa2016.siggraph.org/.
The CG boy model seen in some of these images and used in the research was provided to the research team by Kim Libreri of Epic Games from the ‘Kite Boy’ demo, on which 3Lateral was also responsible for design and rigging.
